Building Enterprise-Grade RAG Applications: A Comprehensive Guide
Introduction
Retrieval-Augmented Generation (RAG) has emerged as the go-to architecture for enhancing language models with custom data. While the concept is straightforward, building production-ready RAG applications requires careful consideration of multiple components and their interactions.
Architecture Overview

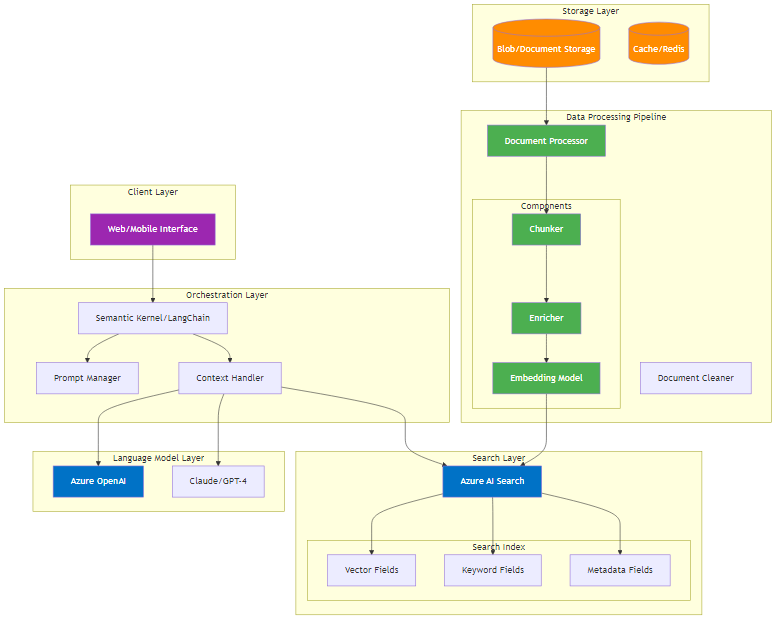
Core Components
RAG Application Flow
-
User Interface Layer
- Handles query input and response display
- Manages user session and context
-
Orchestration Layer
- Implemented via frameworks like Semantic Kernel, Azure ML prompt flow, or LangChain
- Coordinates between search and language model components
- Manages context packaging and prompt engineering
-
Search Layer
- Executes vector, keyword, or hybrid searches
- Returns relevant document chunks
- Handles filtering and ranking
-
Language Model Layer
- Processes search results and user query
- Generates contextual responses
- Ensures response groundedness
RAG Data Pipeline
-
Document Ingestion
- Source document collection
- Format standardization
- Quality checks
-
Document Processing
- Chunking: Semantic segmentation of documents
- Enrichment: Metadata generation and annotation
- Embedding: Vector representation generation
- Persistence: Storage in search indices
Design Considerations
1. Preparation Phase
- Define clear business requirements
- Gather representative test documents
- Create comprehensive query test sets
- Set evaluation metrics
2. Chunking Strategy
- Analyze document structure
- Consider chunking economics
- Choose between approaches:
- Sentence-based
- Fixed-size
- Layout-aware
- ML-based
3. Chunk Enhancement
- Clean and normalize text
- Generate metadata
- Add structural annotations
- Implement quality filters
4. Embedding Selection
- Evaluate model options
- Consider domain specificity
- Test embedding quality
- Monitor performance metrics
5. Search Configuration
- Optimize vector search settings
- Implement hybrid search strategies
- Configure result ranking
- Add filters and facets
6. Evaluation Framework
- Measure groundedness
- Assess completeness
- Track relevancy scores
- Document findings
Best Practices
-
Iterative Development
- Start with baseline implementation
- Measure performance
- Iterate on components
- Document improvements
-
Systematic Evaluation
- Use RAG Experiment Accelerator
- Track metrics across changes
- Maintain test suites
- Version control configurations
-
Production Readiness
- Implement monitoring
- Set up logging
- Plan for scaling
- Consider cost optimization
Azure Implementation Tools
Core Services
-
Azure OpenAI Service
- GPT-4 for response generation
- Ada-002 for embeddings
- Fine-tuning capabilities
-
Azure Cognitive Search
- Vector search
- Semantic search
- Hybrid search capabilities
- Built-in scaling
Development Tools
-
Azure Machine Learning
- Prompt flow for orchestration
- MLflow for experiment tracking
- Model registry
- Pipeline automation
-
Azure Cognitive Services
- Document Intelligence
- Language Studio
- Custom text classification
Infrastructure
-
Azure Container Apps
- Scalable hosting
- Built-in monitoring
- Cost optimization
- Easy deployment
-
Azure Cache for Redis
- Response caching
- Session management
- Rate limiting
Monitoring & Analytics
-
Azure Monitor
- Performance tracking
- Usage analytics
- Cost monitoring
- Alert management
-
Azure Application Insights
- User behavior analysis
- Performance metrics
- Error tracking
- Dependency mapping
Conclusion
Building enterprise-grade RAG applications requires careful attention to each component and their interactions. Success depends on systematic evaluation, iterative improvement, and robust measurement of outcomes. The next articles in this series will dive deeper into each phase of RAG development.
This article is part of a comprehensive series on RAG application development. Stay tuned for detailed explorations of each component in upcoming posts.